Table of contents :
Mistral Large 2: key information and key takeaways
On July 24, 2024, Mistral AI launched Mistral Large 2, a next-generation AI model aimed at breaking current technological barriers. This model brings significant improvements over its previous versions, particularly in code generation, mathematics, and reasoning. This article explores the innovations and exceptional performance of this flagship model.
Ready to transform your business with AI?
Discover how AI can transform your business and improve your productivity.
Technical characteristics and advancements of mistral Large 2
Mistral Large 2 stands out with its cutting-edge technical features, positioning it at the forefront of artificial intelligence models. Thanks to an optimized architecture and impressive processing capacity, it can tackle the most complex challenges with unparalleled precision.
Powerful and versatile architecture
Equipped with 123 billion parameters, Mistral Large 2 offers exceptional computing power. This density allows the model to process complex linguistic tasks with great finesse. Designed to operate efficiently on a single node, it combines flexibility and performance.
Moreover, its extended context window of 128,000 tokens ensures remarkable consistency and relevance during long interactions, whether for extended conversations or voluminous documents.
Excellence in multilingualism and programming
Mistral Large 2 also excels in multilingualism and coding. Capable of handling more than a dozen languages, including French, German, and Spanish, it maintains exemplary consistency in results.
In parallel, it supports over 80 programming languages such as Python, Bash, Java, C++, and JavaScript, offering precision and reliability that rival the most advanced solutions. This versatility makes Mistral Large 2 a powerful tool for code generation and solving complex mathematical problems, significantly outperforming its predecessors in various benchmarks.
Performance comparison of Mistral Large 2 with other models
Mistral Large 2 sets a new benchmark in performance, particularly on the MMLU benchmark where it achieves an accuracy of 84.0%. This result positions it favorably in terms of performance/cost ratio among open-source models.
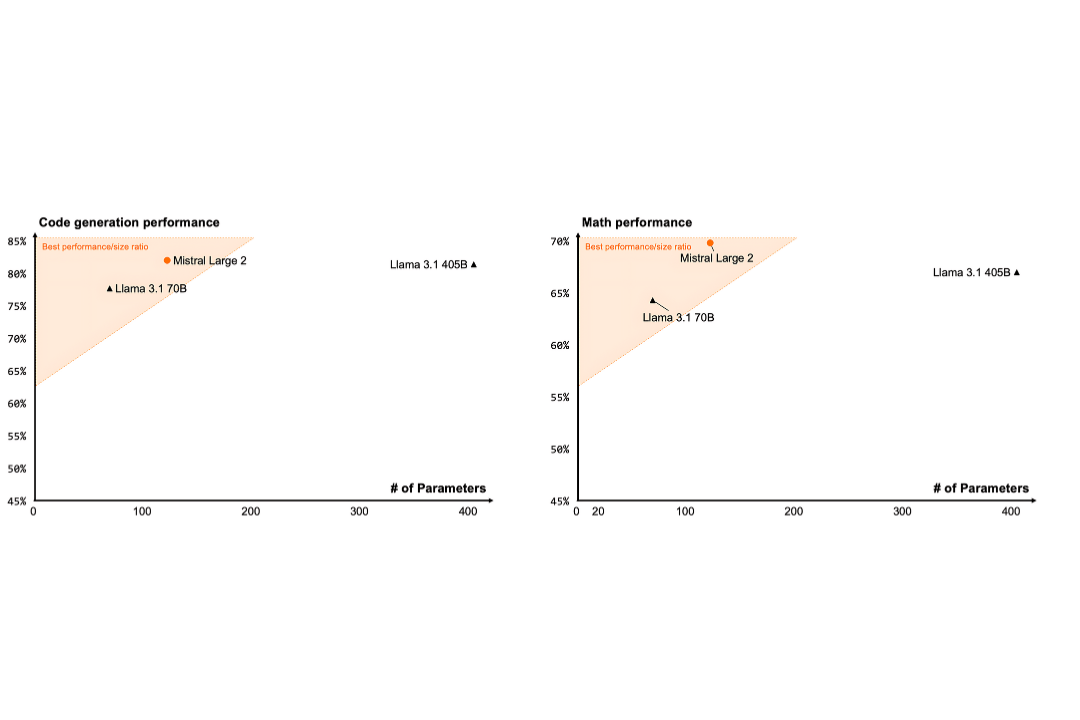
Code generation
The comparative analysis of AI models' performance in code generation reveals interesting results based on the number of parameters. The Mistral Large 2 model, with a relatively low number of parameters, displays a remarkable performance of nearly 85%. This performance places it in the category of models offering the best ratio between performance and size, surpassing other compared models.
In contrast, the Llama 3.1 70B model, despite a higher number of parameters, shows a performance of about 75%. This result, although respectable, is inferior to that of Mistral Large 2. Additionally, Llama 3.1 405B, with the largest number of parameters among the compared models, reaches a performance of about 80%. However, it falls outside the zone of best performance/size ratio.
These results suggest that a high number of parameters is not always correlated with better performance. Mistral Large 2 demonstrates that it is possible to achieve excellent results with an optimized architecture.
Instruction following and hallucination reduction
Mistral Large 2's capabilities in instruction following have been significantly enhanced. This model excels at maintaining the relevance of exchanges throughout interactions, without adding superfluous verbiage. This improvement allows for more efficient management of complex dialogues, ensuring precise and context-appropriate responses.
Simultaneously, Mistral Large 2 has been specially designed to reduce hallucinations and increase response accuracy. Through specific optimizations, the model can clearly identify situations where it lacks necessary information, helping it avoid incorrect answers and erroneous generalizations. These improvements result in increased reliability and reduced errors, making Mistral Large 2 a more robust tool for demanding applications.
Reasoning and knowledge
Mistral Large 2's result on the MMLU test positions it among the best, although it remains slightly below the performance of competing models such as Llama 3.1 (88.6%) and GPT-4o (88.7%).
Regarding the Arc Challenge, Mistral Large 2 distinguishes itself with high scores, reaching 94.2% in 5-shot and 94.0% in 25-shot. Although GPT-4 achieves an impressive score of 96.3% on the Arc Challenge test (25-shot), Mistral Large 2 remains highly competitive and stands out for its cost-effectiveness.
This model outperforms other powerful models like LLaMA 2 70B and GPT-3.5, thus demonstrating a remarkable ability to understand and respond to questions in various contexts.
Function calling
First, what is a function call?
Imagine asking a computer to perform a task, for example, "Calculate 2 plus 3". To execute this task, the computer will use a pre-programmed function, in this case, an addition function. This function call is like a precise order given to the machine.
If we look at the comparison made between Mistral Large, Claude 3.5 Sonnet, Claude 3 Opus, GPT-4.0, and Mistral Large 2 models, we can really see the difference. Mistral Large 2 stands out with an accuracy of about 50%, surpassing models like Claude 3.5 Sonnet, Claude 3 Opus, and GPT-4.0, which display accuracies around 45%. In contrast, previous models like Mistral Large show relatively low accuracy, approximately 15%.
And why is this important for Mistral Large 2?
- Precision in tasks: Thanks to function calling, Mistral Large 2 can execute very specific tasks with high precision. For example, it can generate code, translate languages, or solve mathematical equations.
- Adaptability to user needs: Function calling allows the model to adapt to user requests. If you ask to generate a poem on a specific topic, the model can use the right functions to create that poem.
- Efficiency for practical applications: In the real world, many applications need to execute precise tasks. Function calling makes Mistral Large 2 very effective for these applications.
Thus, Mistral Large 2 offers remarkable performance and excellent cost-effectiveness, positioning it as a serious competitor to models like Llama 3.1 and GPT-4. Although GPT-4 slightly outperforms Mistral Large 2 on some evaluations, the latter remains a very competitive choice.
author
OSNI

Published
August 26, 2024
Ready to transform your business with AI?
Discover how AI can transform your business and improve your productivity.