Table of contents :
Llama 4: Meta's multimodal revolution challenging GPT-4
Imagine processing 7,500 pages of text at once. This is now possible with Llama 4, the revolutionary artificial intelligence model unveiled by Meta on April 5, 2025. With a context window reaching 10 million tokens, this new generation of AI pushes the boundaries of what was previously possible.
Ready to transform your business with AI?
Discover how AI can transform your business and improve your productivity.
Studies show that 85% of complex professional tasks require analyzing voluminous documents - a challenge that Llama 4 brilliantly addresses thanks to its innovative architecture. In this article, discover how this technological breakthrough is transforming the AI landscape and why it could eclipse competitors like GPT-4 in certain application domains.

Llama 4: Meta's major innovation decoded
What really sets Llama 4 apart from previous generations?
Llama 4 represents a considerable technological leap compared to its predecessor, Llama 3. While Llama 3 already excelled in text processing, Llama 4 introduces a true breakthrough with its native multimodal capability. This evolution allows simultaneous analysis of text and images from the pre-processing phase, offering a much richer and more nuanced contextual understanding.
The other major advancement concerns the context window. Llama 3 was capped at 128,000 tokens, already impressive at the time of its release. Llama 4 shatters this record with a capacity of up to 10 million tokens for the Scout model. This improvement of nearly 80 times allows ingesting and analyzing entire document corpora without losing context.
Finally, the fundamentally redesigned architecture of Llama 4 abandons the traditional approach of dense models to adopt a much more efficient MoE (Mixture of Experts) structure, inspired by Chinese advances in the field. This major innovation will soon be available on your Swiftask AI aggregator, allowing users to explore the full potential of this new optimized architecture.
The three flagship models: Scout, Maverick, and Behemoth
Meta deploys Llama 4 in three distinct variants, each addressing specific needs and constraints:
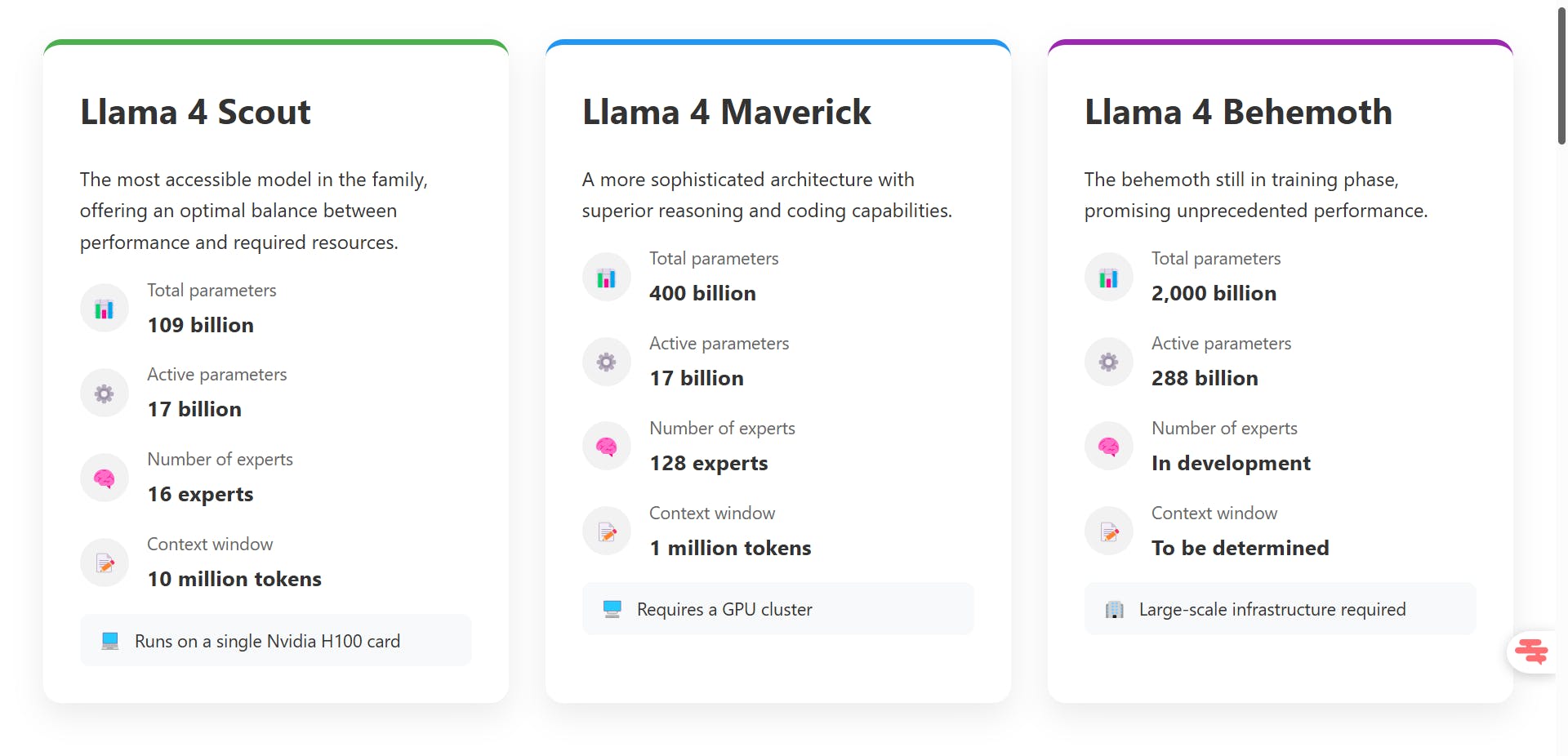
Llama 4 Scout positions itself as the most accessible model. With 109 billion total parameters, of which only 17 billion are simultaneously active thanks to its 16 experts, it offers an optimal balance between performance and required resources. Its 10 million token context window makes it the champion in all categories for analyzing voluminous documents. Scout can run on a single Nvidia H100 graphics card, making it accessible to medium-sized businesses.
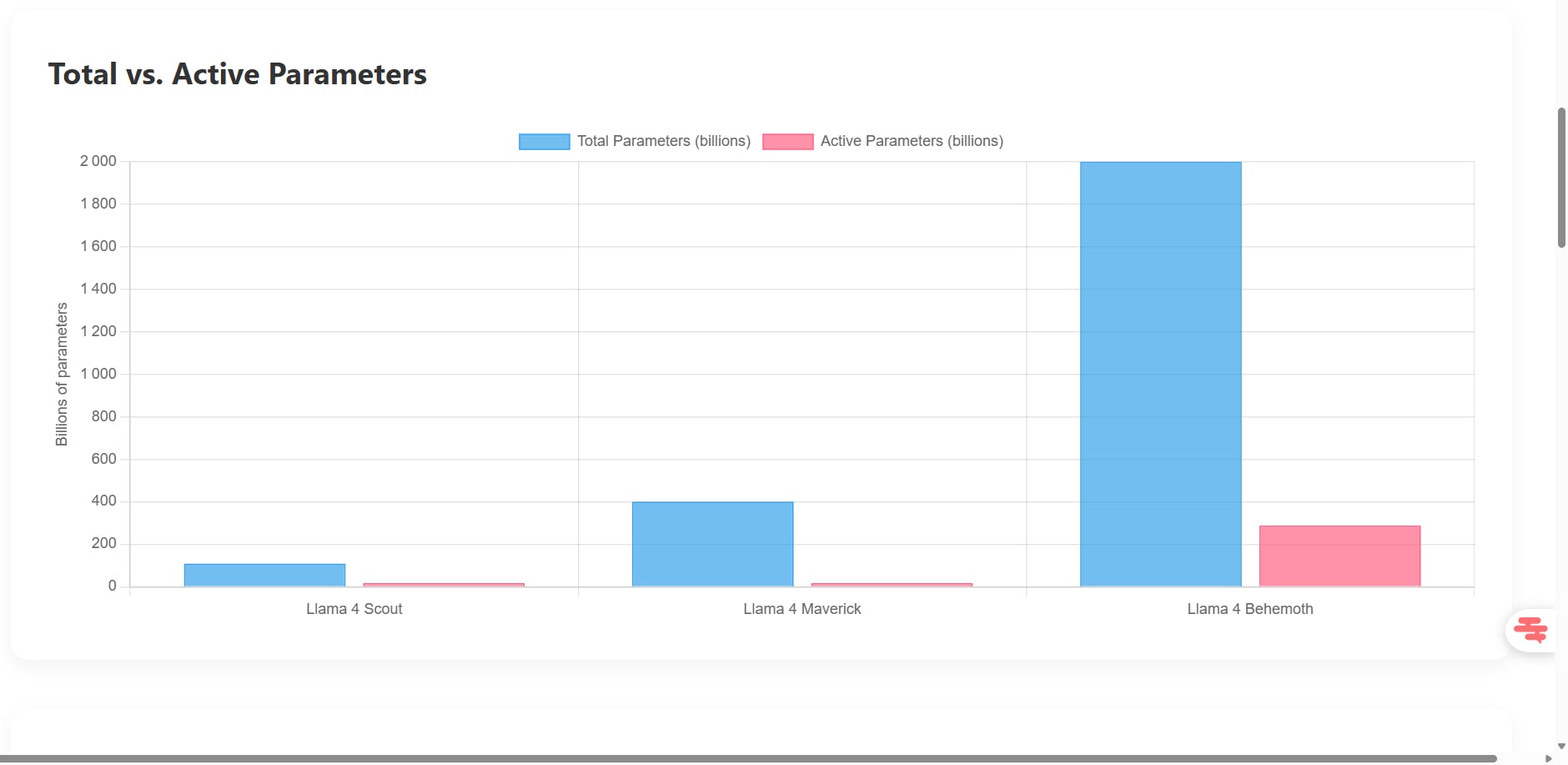
Llama 4 Maverick steps up in power with 400 billion total parameters (still 17 billion active) distributed across 128 experts. This more sophisticated architecture gives it superior reasoning and coding capabilities, directly rivaling GPT-4o and Gemini 2.0 Flash. Its context window of 1 million tokens remains impressive, though reduced compared to Scout. Maverick requires a cluster of GPUs to function efficiently.
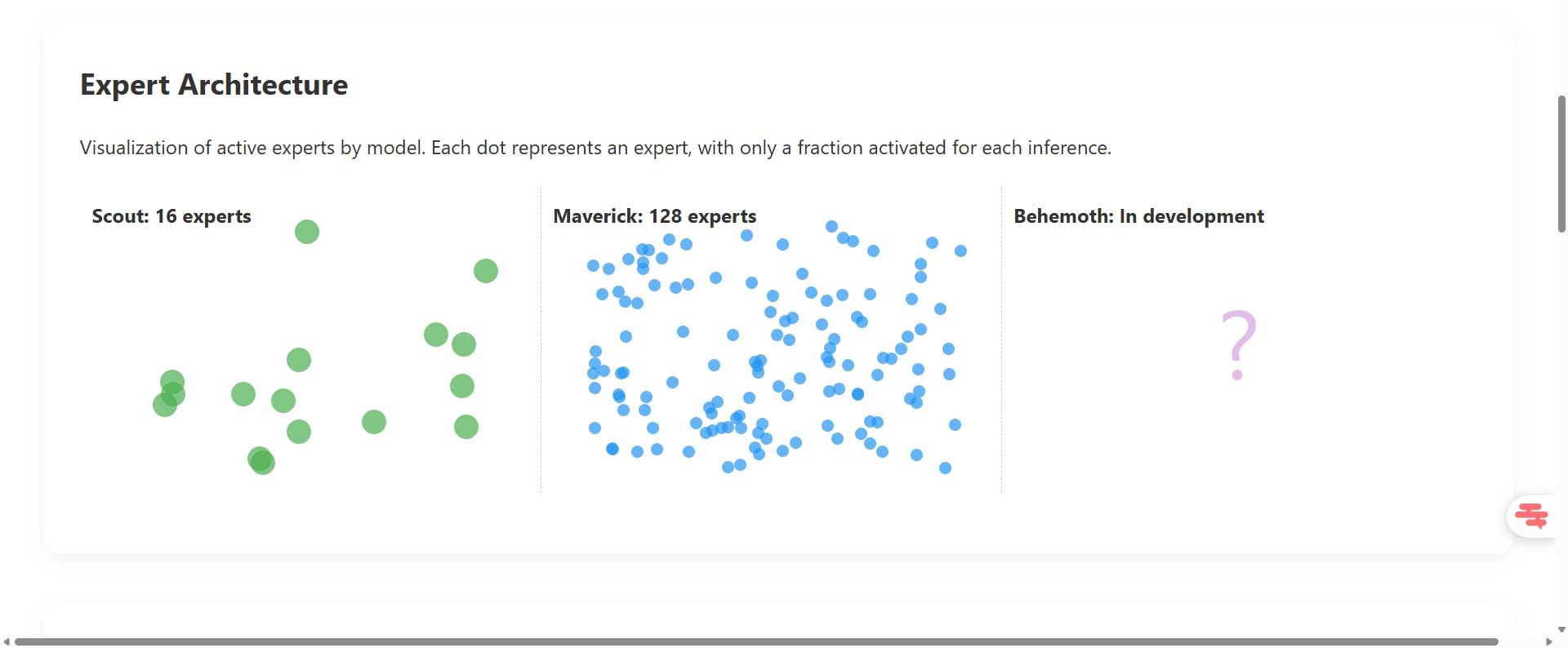
Llama 4 Behemoth, still in the training phase, promises unprecedented performance with its 2 trillion total parameters and 288 billion active ones. This behemoth aims to surpass all existing models and establish new standards in generative AI.
Meta's open source strategy versus proprietary giants
With Llama 4, Meta continues its philosophy of openness, running counter to the proprietary models of OpenAI, Anthropic, or Google. This open-source approach, however, comes with limitations. The models are accessible under license but with restrictions on commercial use and ethical safeguards.
This strategy allows Meta to benefit from an ecosystem of developers contributing to model improvement while maintaining a competitive advantage through its optimized implementations. The company also integrates these models into its applications like WhatsApp, Instagram, and Facebook in 40 countries.
This intermediate position between openness and control presents a challenge for giants with closed models like OpenAI, which must justify their restrictions in the face of high-performing and more accessible alternatives.
MoE architecture: The power secret of Llama 4
How does Mixture of Experts technology work?
The Mixture of Experts (MoE) architecture represents a paradigm shift in the design of large language models. Unlike traditional dense models where all parameters are activated for each inference, MoE models divide their parameters into specialized subsets called "experts."
For each input or token to process, a mechanism called a "router" determines which experts are most relevant and activates only those. For example, in Llama 4 Scout, only 2 experts out of the 16 available are activated for each token, meaning that only 12.5% of the total parameters are used at any given time.
This specialization allows each expert to develop specific skills in particular domains: some may excel in mathematical analysis, others in linguistic comprehension or spatial reasoning. The result is a system that is more performant and more efficient than traditional dense architectures.
The revolutionary computational efficiency of specialized experts
The major advantage of the MoE architecture lies in its computational efficiency. Meta reports a 60% reduction in computational costs compared to equivalent dense models. This efficiency translates into several concrete benefits:
- Faster inference: Llama 4 Scout can generate responses up to 3 times faster than a comparable dense model.
- Reduced energy consumption: Selective parameter activation significantly decreases electricity consumption, a crucial issue for large-scale deployments.
- Increased accessibility: More powerful models can run on more modest hardware, democratizing access to advanced AI.
- Improved scalability: The MoE architecture allows for considerably increasing the total size of models without a proportional explosion in inference costs.
This efficiency represents a major competitive advantage in a context where the operational costs of AI models constitute a considerable economic challenge for businesses.
Comparison with traditional AI model architectures
Dense models like GPT-4 and Claude 3 Opus activate all of their parameters for each token processed. This approach presents certain advantages in terms of consistency and stability but suffers from fundamental inefficiencies.
A dense model of 70 billion parameters systematically mobilizes all of its resources, even for simple tasks. In comparison, Llama 4 Maverick with its 400 billion total parameters uses only 17 billion at a time, while offering superior performance on many benchmarks.
This architectural difference explains why Meta can offer models with capabilities comparable to those of GPT-4 with more modest hardware requirements. It also illustrates why Chinese giants like Baidu and ByteDance adopted this MoE approach before Western actors.
The flexibility of the MoE architecture also allows for finer specialization and better adaptation to specific domains, paving the way for highly optimized vertical models.
Unprecedented native multimodal capabilities
Why does early text-image fusion change the game?
Llama 4's multimodality rests on a fundamental innovation: the early fusion of text and image modalities. Unlike traditional approaches that process different modalities separately before combining them late in the pipeline, Llama 4 integrates this information from the first layers of the neural network.
This approach allows for a much richer contextual understanding. The model can establish deep correlations between textual and visual elements, understand the nuances of an image based on accompanying text, and vice versa. For example, when faced with a complex graph accompanied by textual explanations, Llama 4 can grasp the relationships between visual data and written comments in a unified manner.
This early fusion also allows for preserving spatial relationships between textual and visual elements in documents such as scientific reports, technical manuals, or business presentations, offering a contextual understanding impossible with late fusion systems.
Simultaneous processing of 48 images: concrete applications
Llama 4's ability to analyze up to 48 images simultaneously opens revolutionary perspectives in many domains:
Medical: A radiologist can submit a series of medical images of the same patient (MRI, CT scan, X-rays) with the textual history to obtain a complete comparative analysis and diagnostic suggestions.
E-commerce: Platforms can instantly analyze entire product catalogs with their descriptions to identify inconsistencies, suggest improvements, or generate optimized descriptions.
Real estate: Agents can submit all photos of a property with its description to obtain a complete evaluation, improvement suggestions, or generate optimized listings.
Scientific research: Researchers can simultaneously analyze temporal series of microscopic or satellite images with their annotations to identify subtle trends or anomalies.
This massive parallel processing capability represents a significant advantage over models limited to just a few images at a time.
Current limitations of Llama 4's multimodal functionalities
Despite its impressive advances, Llama 4's multimodal capabilities still present certain limitations:
Linguistic restriction: Multimodal functionalities are currently only available in American English in Meta's consumer applications, limiting their global accessibility.
Restricted modalities: Although performant on text and images, Llama 4 does not yet natively handle audio or video as input modalities, unlike some competitors such as Gemini 1.5 Pro.
Potential biases: Like any AI model, Llama 4 can reproduce or amplify biases present in its training data, particularly problematic in image interpretation.
Visual hallucinations: The model can sometimes "hallucinate" elements not present in images or misinterpret ambiguous visuals, a common challenge to all current multimodal systems.
Meta is actively working to resolve these limitations, notably via continuous improvements to the model and fact-checking mechanisms to limit hallucinations.
Titanic context window and professional applications
What advantages does a 10 million token memory offer?
Llama 4 Scout's 10 million token context window represents a monumental advance, equivalent to approximately 7,500 standard pages. This capacity fundamentally transforms interaction with AI systems:
Holistic understanding: The model can ingest and understand entire document corpora, maintaining contextual coherence across all content. Gone are the problems of forgetting or information fragmentation.
Extended conversations: Exchanges can extend over thousands of turns without loss of context, allowing for prolonged collaborations on complex projects.
Comparative analysis: Multiple voluminous documents can be analyzed simultaneously to identify similarities, contradictions, or complementarities, a task practically impossible for models with limited context.
Deep personalization: The model can integrate an extremely detailed interaction history to offer responses perfectly adapted to the specific preferences and needs of the user.
This extended context window transforms AI from a simple tool for punctual responses into a true collaborator capable of maintaining deep understanding over time.
Analysis of complete codebases and technical documentation
In the software development domain, Llama 4 revolutionizes established practices:
Global code understanding: The model can ingest entire codebases, sometimes comprising millions of lines spread across hundreds of files. This overview allows it to identify patterns, vulnerabilities, or optimization opportunities invisible during fragmented analyses.
Exhaustive documentation generation: Beyond simple comments, Llama 4 can produce complete, contextual, and coherent technical documentation, explaining complex interdependencies between components and architectural choices.
Intelligent refactoring: By understanding the entirety of a codebase, the model can suggest major restructurings that preserve functionalities while improving maintainability, security, or performance.
Accelerated onboarding: New developers can dialogue with Llama 4 to quickly understand complex codebases, drastically reducing the time needed to become productive on a new project.
Companies like Cloudflare and Hugging Face have already integrated Llama 4 into their development workflows, reporting productivity gains of 30 to 45%.
Revolution in processing legal and medical documents
The legal and medical domains, characterized by considerable document volumes, particularly benefit from Llama 4's extended context window:
Complete legal analysis: Law firms can submit the entirety of a case file - contracts, jurisprudence, testimonies, correspondences - to obtain a global analysis identifying inconsistencies, risks, or opportunities.
Medical literature review: Researchers can simultaneously analyze hundreds of scientific studies to identify emerging patterns, contradictions, or promising research avenues.
Longitudinal medical records: A patient's complete medical history, sometimes spanning decades, can be analyzed to identify subtle correlations between symptoms, treatments, and long-term results.
Regulatory compliance: Companies can verify the compliance of their voluminous documents (internal policies, procedure manuals) with complex regulatory frameworks like GDPR or Sarbanes-Oxley.
In these sectors where exhaustiveness and precision are crucial, Llama 4's ability to maintain context over massive document volumes represents a decisive advantage.
Practical applications of Llama 4 for users
How can developers leverage Llama 4 today?
Developers have several options for integrating the power of Llama 4 into their projects:
Hugging Face: The platform offers optimized versions of Llama 4 Scout and Maverick, accessible via API or downloadable for local deployment. Developers can use pre-trained models or fine-tune them for specific use cases.
Cloudflare Workers AI: This serverless solution allows integrating Llama 4 Scout into web applications without dedicated infrastructure. The model is accessible via a simple REST API, with usage-based billing.
LlamaIndex and LangChain: These frameworks facilitate creating RAG (Retrieval-Augmented Generation) applications exploiting Llama 4's extended context window to navigate massive document bases.
Meta AI Studio: This platform allows developers to customize Llama 4 for specific needs via simplified fine-tuning techniques and integrated evaluation tools.
To get started, developers can begin with simple projects like document assistants or code analysis tools before tackling more complex applications fully exploiting the model's multimodal capabilities.
Innovative use cases for businesses and content creators
Businesses and content creators are quickly discovering transformative applications of Llama 4:
Integrated multichannel marketing: Simultaneous analysis of cross-media advertising campaigns (text, images, performance data) to identify synergies and optimize overall ROI.
Augmented content production: Generation of series of coherent thematic articles with relevant illustrations, maintaining a consistent editorial voice across voluminous editorial projects.
Competitive market analysis: Parallel processing of annual reports, press releases, and digital presences of competitors to identify positioning, strengths, and weaknesses.
Evolving training and documentation: Creation and maintenance of internal training systems that automatically adapt to evolutions in products, procedures, and regulations.
Automated strategic monitoring: Continuous analysis of sectoral information sources to identify emerging trends, threats, and opportunities, with personalized syntheses by department.
These applications allow organizations of all sizes to exploit volumes of information previously impossible to process efficiently, transforming raw data into actionable insights.
Access and integration of Llama 4 in your personal projects
For individual users and small teams, Llama 4 offers accessible integration possibilities:
Conversational interfaces: Applications like LM Studio, Ollama, or GPT4All allow locally running optimized versions of Llama 4 Scout on relatively powerful personal computers.
Plugins for creative environments: Extensions for Photoshop, Figma, or Canva exploit Llama 4's multimodal capabilities to suggest design improvements or generate creative variations.
Personalized research assistants: Creation of agents specialized in your areas of interest, capable of analyzing and synthesizing vast document corpora specific to your sector.
No-code applications: Platforms like Bubble or Webflow now offer simplified integrations with Llama 4, allowing creation of AI applications without advanced technical skills.
Browser extensions: Tools like Merlin or Glasp integrate Llama 4 to offer analysis and synthesis capabilities directly in your daily web browsing.
The rapidly expanding ecosystem around Llama 4 democratizes access to this advanced technology, allowing everyone to explore its potential without massive investments in infrastructure or technical expertise.
Llama 4 represents a major turning point in the evolution of artificial intelligence models. Thanks to its revolutionary MoE architecture, native multimodal capabilities, and titanic context window, it pushes the boundaries of what is possible in generative AI. Meta thus directly challenges giants like OpenAI and Google while democratizing access to these advanced technologies.
The practical applications of Llama 4 are already transforming numerous sectors, from programming to medicine, law, and marketing. Its ability to simultaneously process vast document corpora and dozens of images opens unprecedented possibilities for professionals and creators alike.
As the ecosystem continues to develop around these models, we have probably only scratched the surface of their potential. The upcoming arrival of Llama 4 Behemoth promises to extend these capabilities even further, while Meta's open-source approach fosters collaborative innovation and the emergence of specialized applications.
One thing is certain: Llama 4 marks the beginning of a new era for AI, where extended contextual understanding and the harmonious fusion of textual and visual modalities become the norm rather than the exception.
author
OSNI

Published
April 09, 2025
Ready to transform your business with AI?
Discover how AI can transform your business and improve your productivity.